Forward 和 Backward
forward和backward是一个Net的基本计算。
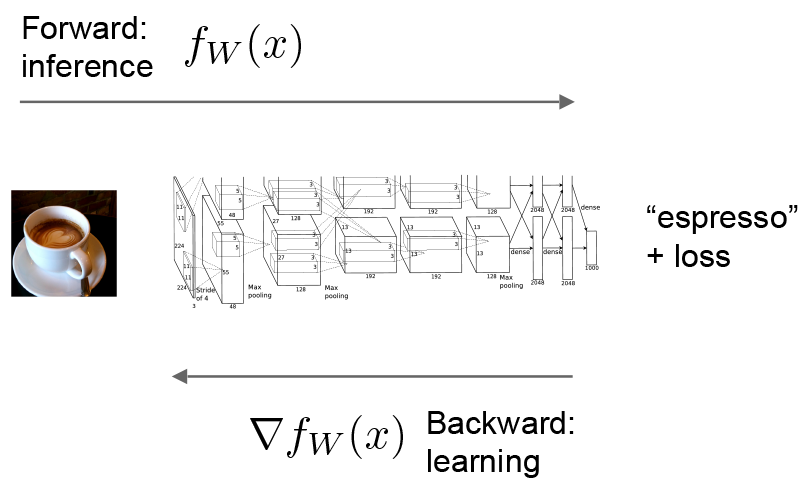
我们来考虑一个简单的logistic regression 分类器.
Forward计算出用来推断(inference)的输出,在forward过程中,caffe把各层的计算结果组装成模型所表达的”函数”值,这个过程是自底向上传播的。
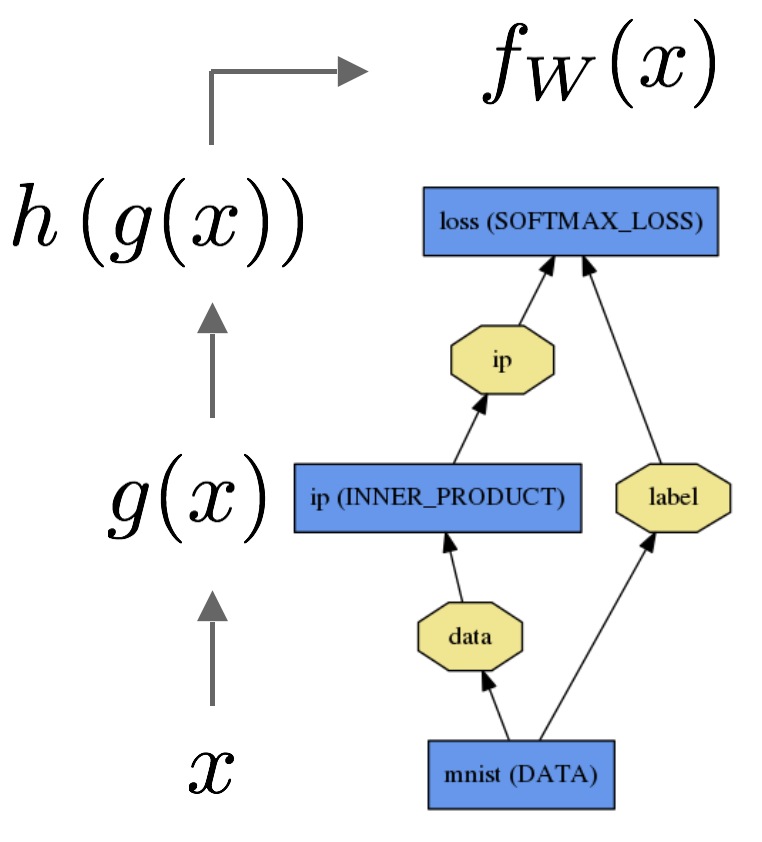
图中数据$x$经过一个内积层成为$g(x)$,然后再经过一个softmax分类器成为h(g(x)),softmax的loss为$f_w(x)$.
Backward把顶层的损失loss向底层传播,向底层传播是通过自动求导技术生成梯度的。这个过程是自顶向下的。
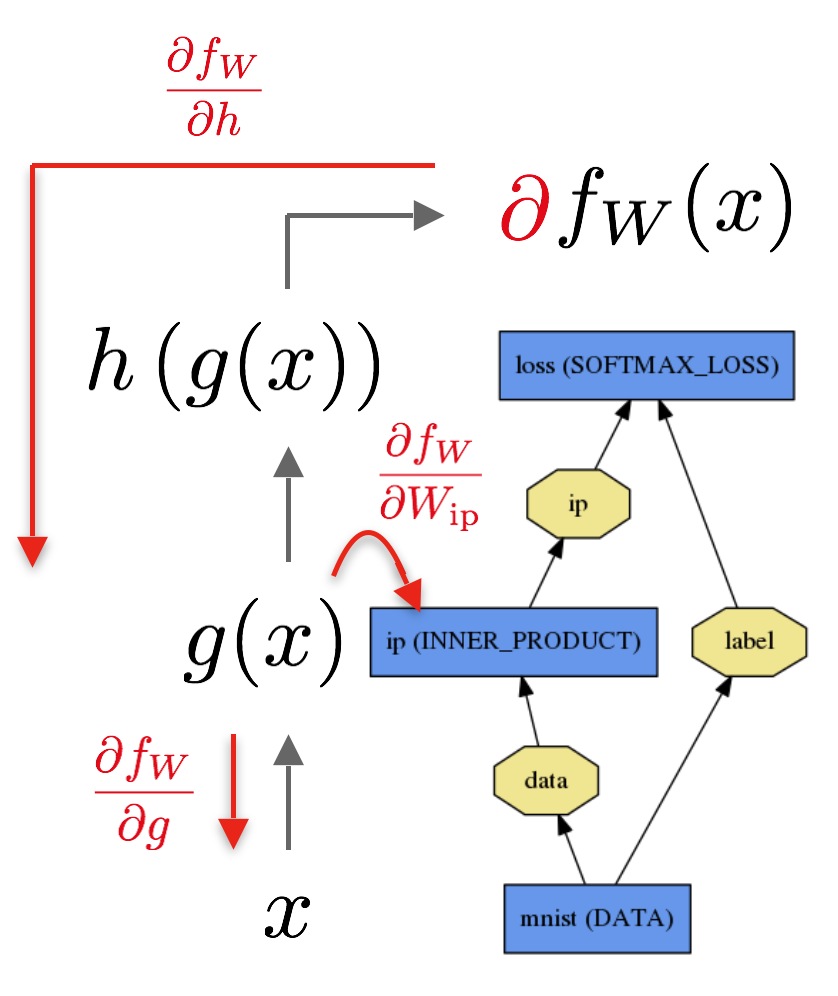
反向传播用顶层的损失函数的输出作为输入,通过公式$\frac{\partial f_W}{\partial h}$ 计算顶层的梯度,剩下层的梯度是利用链式法则逐层计算的。那些带有参数的层,比如INNER_PRODUCT层,通过它们的参数$\frac{\partial fW}{\partial W{\text{ip}}}$来计算梯度(其实这都是由自动求导技术在前向传播计算好的,反向传播的时候只是收集一下,和动态规划的思想类似)。
当你定义好网络的时候,这些计算就已经设置好了,caffe会自动为你做前向和后向传播计算.
Net::Forward()和Net::Backward()方法会在前向和后向的过程中把各层的Layer::Forward()和Layer::Backward()函数执行,并把结果收集起来。- 每个
layer类型都有一组forward_{cpu,gpu}()和backward_{cpu,gpu}()方法来根据运行的mode来调用相应的方法计算本层的结果。由于条件限制或者为了方便起见,一个layer可能只实现了CPU或者GPU模式的代码。
Solver是用来对整个网络求解的,它先调用forward来产生输出和loss,然后调用backward来产生gradient,最后把梯度合并用来在优化步骤中更新权重。把功能分割成Solver,Net和Layer使得Caffe高内聚低耦合,易于扩展。
有关forward和backward的详细内容请参看Layer catalogue